01/02/2022 Google Hashcode - Pizza Practice
Résolution du puzzle d'entrainement du google hash code 2022

Introduction
Avec un groupe de collègues, nous nous sommes inscrits au Google hashcode 2022, qui se déroulera le 24 février 2022.
C'est la première fois que je suis inscrit à une compétition de code qui ne se déroule pas sur la plateforme CodinGame à laquelle je suis habitué. En attendant le concours, Google propose un exercice de pratique pour se familiariser avec le fonctionnement de la plateforme : téléchargement du jeu de donnée, gestion des I/O, lecture/écriture de fichiers, etc.
Le puzzle est relativement simple en apparence. Vous êtes le gérant d'une pizzeria sur le point d'ouvrir et vous avez déjà un fichier clients. Ce fichier contient la liste de vos clients réguliers ainsi que leurs préférences c'est-à-dire ce qu'ils aiment sur leur pizza et ce qu'ils détestent sur leur pizza.
Malin et un peu faignant, vous décidez de ne mettre à la carte qu'une seule et unique recette de pizza : celle qui plaira au plus grand nombre de vos clients.
À savoir que pour qu'un client soit pleinement satisfait, il faut que la recette de la pizza réponde à deux critères :
- Tous les ingrédients que le client aime doivent être présent sur la pizza.
- La pizza peut contenir des ingrédients en plus à condition qu'aucun ne soit dans la liste des ingrédients détestés du client.
On fait chauffer notre plus beau four à feu de bois, nous voila partis !
Approche Naïve
Les jeux de données se présentent de cette manière :
1322 cheese peppers3041 basil51 pineapple62 mushrooms tomatoes71 basil- La 1ère ligne contient le nombre de clients présents dans le fichier.
- Ensuite par groupe de deux lignes les préférences de chaque client :
- La première ligne contient le nombre d'ingrédients que le client aime, suivi de la liste de ces ingrédients.
- La deuxième ligne contient le nombre d'ingrédients qu'il déteste, suivi de la liste de ces ingrédients.
Une fois le code de la lecture de fichier, de parsing et d'écriture des fichiers de résultats fait, je réfléchis à une première solution.
Je fais l'inventaire de tous les ingrédients possibles parmi les ingrédients aimés et détestés de tous mes clients. Puis je retire tous les ingrédients détestés de mes clients. Ainsi j'obtiens une recette qui ne contient aucun des ingrédients détestés de tous mes clients.
La solution ressemble à ceci :
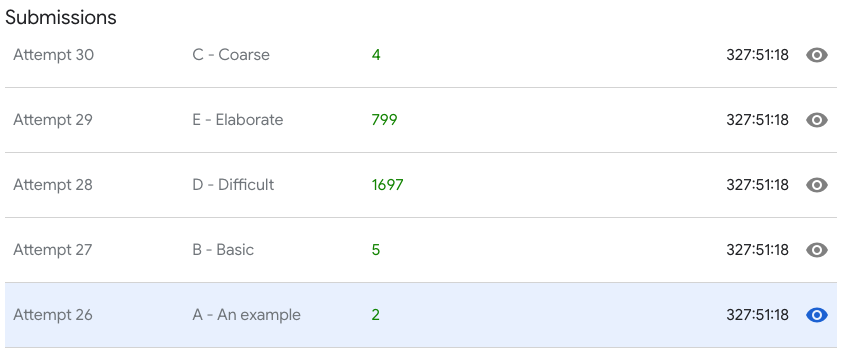
1for i in range(client): 2 line = f.readline().strip().split() 3 number_like = line.pop(0) 4 ingredients += line 5 6 line = f.readline().strip().split() 7 number_dislike = line.pop(0) 8 disliked += line 9 10for i in disliked:11 if i in ingredients:12 ingredients.remove(i)13 14ingredients = list(set(ingredients))Voici les résultats pour cette solution (en vert le nombre de clients satisfaits pour chaque jeu d'inputs)
Algorithme Génétique
Ok, je dois pouvoir faire mieux. Je réfléchis, fais quelques recherches et décide de mettre en place un algorithme génétique.
Je ne suis pas très à l'aise avec ce type d'algorithme. Je ne l'ai mis en place qu'une seule fois lors d'un tuto trouvé sur tech.io.
Qu'à cela ne tienne ça me fera progresser et pratiquer !
- Génération d'une population de base : en l'occurrence ici une population de 100 recettes de pizza,
- Sélection des 20 meilleures recettes : pour cela je créé une fonction qui retourne le score d'une pizza selon la base client
- Sélection de 30 recettes aléatoires parmi les non-déjà sélectionnées,
- Reproduction jusqu'à atteindre de nouveau une population de 100 recettes,
- Mutation des recettes "enfant" issues de la reproduction. En changeant au hasard un ingrédient de la recette par un autre non déjà présent.
Après quelque temps mon algo "fonctionne" mais sur les jeux de tests les plus grands ("d_difficult" et "e_elaborate"), mon algo plafonne et s'enferme autour d'une valeur sans en sortir. J'essaye plusieurs fois de changer quelques paramètres, muter plus de recettes, changer le nombre de recettes sélectionnés, ré-introduire un certain nombre de recettes nouvelles par cycle mais rien n'y a fait.
Algorithme de Hill Climbing
L'algorithme de Hill Climbing est un algorithme de recherche local, glouton. Il permet de chercher une solution "optimale" à un problème. Il nécessite la mise en place de 3 étapes :
- Définition d'un point de départ,
- Recherche de solutions voisines,
- Évaluation de notre solution de départ et comparaison aux solutions voisines, Si une solution voisine est plus optimale, on remplace la solution de départ par cette solution voisine, sinon on continue avec la solution initiale. Ensuite on boucle sur les étapes 2 et 3 jusqu'à atteindre la condition de sortie.
Première solution : Je génère donc une recette de départ contenant un seul ingrédient et puis j'ajoute un nouvel ingrédient (étape 2). Je compare le score de cette nouvelle recette à l'ancienne, s'il est plus élevé, je conserve cette nouvelle recette sinon je conserve l'ancienne. Retour à l'étape 2 et ainsi de suite.
Ma condition de sortie est la suivante : si le score n'évolue pas durant X tours de boucle je break et récupère la meilleure solution.
L'algorithme fonctionne, mais il n'est pas très performant. J'atteins des scores pas beaucoup plus élevés que ceux de ma solution naïve. D'autant plus que des collègues, qui ont implémenté une autre solution, ont des scores plus performants. Il est donc possible de faire mieux.
1--------------- FILE a_an_example ---------------- 2--- fichier a_an_example | score : 2 3--------------- FILE b_basic ---------------- 4--- fichier b_basic | score : 5 5--------------- FILE c_coarse ---------------- 6--- fichier c_coarse | score : 1 7--------------- FILE d_difficult ---------------- 8--- fichier d_difficult | score : 1655 9--------------- FILE e_elaborate ----------------10--- fichier e_elaborate | score : 933En effet, certains ingrédients ajoutés pourraient ne pas être présents dans une autre recette plus optimale. La méthode incrémentale n'est pas une bonne approche, il faudrait supprimer certains ingrédients.
J'essaye donc une nouvelle approche : ajouter aléatoirement un ingrédient et supprimer aléatoirement un ingrédient. Les résultats sont bons sur les grands jeux de données, mais moins performants sur les petits jeux de données.
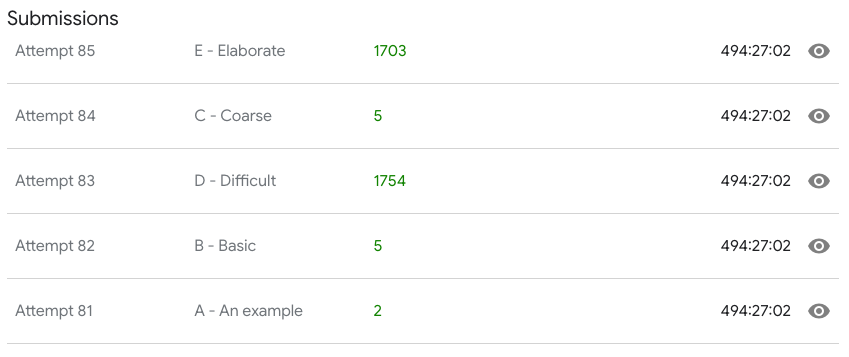
1--------------- FILE a_an_example ---------------- 2--- fichier a_an_example | score : 1 3--------------- FILE b_basic ---------------- 4--- fichier b_basic | score : 1 5--------------- FILE c_coarse ---------------- 6--- fichier c_coarse | score : 3 7--------------- FILE d_difficult ---------------- 8--- fichier d_difficult | score : 1780 9--------------- FILE e_elaborate ----------------10--- fichier e_elaborate | score : 1321Je continue à chercher d'autres idées sur Google et je tombe sur le Github d'une personne qui utilise la même approche que la mienne, mais avec plus de succès. Il a choisi une personne qui n'aime pas la recette et ajoute les ingrédients que la personne aime à la recette et supprime les ingrédients que la personne n'aime pas à la recette. Il compare le score de cette nouvelle recette à l'ancienne recette, si le score est plus élevé que l'ancienne, il garde cette nouvelle recette.
Je modifie mon code pour utiliser la même idée pour la sélection des voisins. Les résultats sont longs à arriver, très long, ... En fait tellement long que j'ai dû attendre le lendemain matin pour les consulter. Les résultats sont bons, meilleurs que toutes mes précédentes solutions !
Malgré tout, la solution est très longue à s'exécuter. Trop bien ! Mais ça me turlupine : comment puis-je optimiser le temps d'exécution ?
Optimisations
Je fais plusieurs recherches, je commence par les tricks "classiques" d'optimisation que je trouve sur python :
- Importer le strict nécessaire comme :
1from random import choice2# au lieu de3# import random- Utiliser les listes de compréhension plutôt que les boucles classiques.
Malgré cela, les jeux de tests les plus longs mettent énormément de temps à s'exécuter jusqu'à ce que ...
Je transforme la liste d'ingrédients en set ainsi que les listes d'ingrédients aimés/détestés en sets aussi. Les sets sont un type de structure de données semblable aux listes à la différence que les sets ne peuvent pas contenir de doublon (parfait ma recette ne doit pas en contenir).
De plus, les sets sont très performants lors des opérations de comparaison et de parcours. Ce que mon code fait énormément notamment dans la fonction d'évaluation du score d'une recette.
Et tadah :
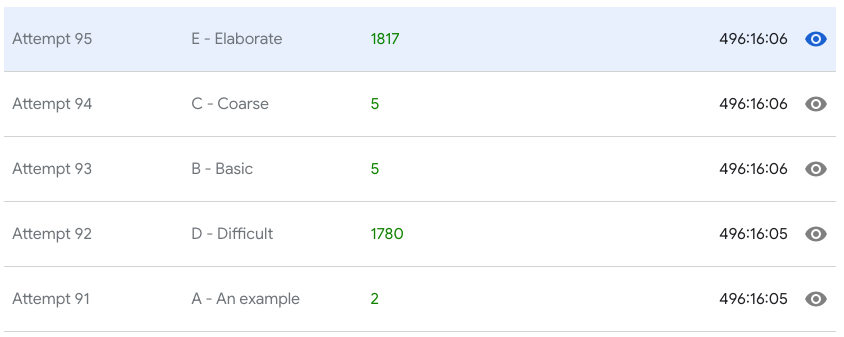
1--------------- FILE a_an_example ---------------- 2--- fichier a_an_example | score : 2 | temps : 0.004887104034423828 secondes --- 3--------------- FILE b_basic ---------------- 4--- fichier b_basic | score : 5 | temps : 0.00020813941955566406 secondes --- 5--------------- FILE c_coarse ---------------- 6--- fichier c_coarse | score : 5 | temps : 0.01146697998046875 secondes --- 7--------------- FILE d_difficult ---------------- 8--- fichier d_difficult | score : 1779 | temps : 44.253543853759766 secondes --- 9--------------- FILE e_elaborate ----------------10--- fichier e_elaborate | score : 1800 | temps : 93.31445813179016 secondes ---De quelques heures, je suis passé à quelques secondes ! J'ai même pu augmenter le nombre qui permet à mon code de s'arrêter ce qui me permet d'obtenir des résultats plus précis.
Conclusion
Cet exercice de pratique est une super initiation aux compétitions de code de Google. Il m'a permis de me mettre en jambes sur la manière dont fonctionne les compétitions de code autres que celles de Codingame, qui possède son propre IDE et où les jeux de données sont envoyés directement dans l'IDE. Simple à comprendre, mais difficile à optimiser. Le puzzle est fun et très intéressant. J'ai découvert un nouveau type d'algorithme, mais aussi que les sets peuvent se révéler bien plus performants que les listes pour certaines opérations. Vivement le 24 février pour la vraie compétition cette fois-ci :)